Разбираемся с тормозной файловой системой, часть 1: теория
I/O = input/output
Кто хотя бы слегка касался темы производительности дисковых систем, слышал про такую единицу измерения как IOps. Ими любят кичиться именитые производители дисковых массивов или, например, часто могут обсуждать DBA (админы баз данных).
Но дело в том, что эти самые IO настолько динамическая и не-атомарная операция, что подсчитывать их в профессиональных кругах считается моветоном.
Так что-же такое этот IO? В прямом переводе это операция ввода-вывода, подразумевая некое действие, связанное с запросом информации от источника к приемнику. Если уж мы завели разговор о дисках, то информация должна перетекать от какой-то программы-источника на диск, или наоборот, чтение с диска этой программой-приемником.
Давайте обратимся к схеме, которую я так старательно составлял 🙂
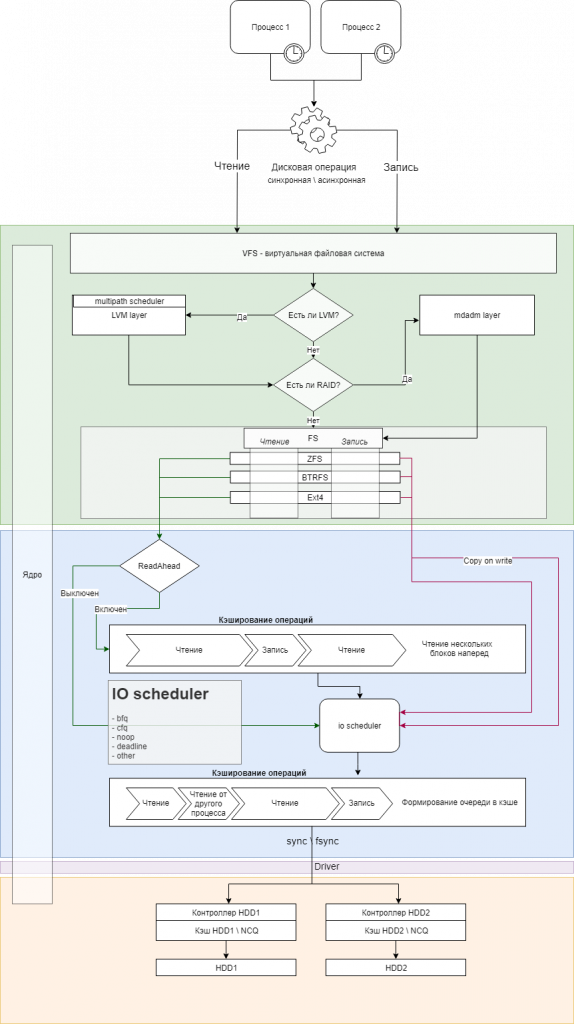
Итак, некий процесс вдруг захотел что-то прочитать с диска\записать на диск. Сразу же встречается первая оговорка – какая эта операция, синхронная или асинхронная? Это зависит только от автора(-ов) программы: для некоторых задач обязательно дисковая операция должна завершиться, прежде чем процесс продолжит свое выполнение, для других задач это неважно – параллельно можно заняться другими делами. Это условие исключительно диктуется целями, которые ставятся перед программой, но, впрочем, может быть и косяком программиста. Следует иметь в виду, что чтение тоже может быть асинхронным – почему нет? I/O операция это всего лишь запрос, как уже упоминалось, программе достаточно отправить этот запрос, а вот можно ли что-то делать пока ответ приходит – опять же зависит от ситуации. Все это напоминает tcp и udp, что, по-моему, очень удачное сравнение.

Слой пониже представляет собой достаточно хитрую абстракцию, с которой работает наша ОС. VFS – виртуальная файловая система, должна предоставлять единообразный уровень представления файловой системы. Приложению должно быть абсолютно пофигу на какую в итоге файловую систему оно пишет\читает данные, это вне его компетенции (если это не приложение для работы с файловой системой, конечно 🙂 ). Ему не нужно знать есть ли у нас менеджер томов, есть ли raid-массивы, Ceph, iSCSI, SAN, и прочее-прочее, тысячи их. Так что полномочия самого процесса, выполняющего дисковую операцию, как говорится “всё”.
Синий слой – механизм формирования очереди запросов к “железу”. Так как классический жесткий диск, как и шестьдесят лет назад, представляет собой быстро крутящиеся блинчики на шпинделе, то подход к тому, какие данные и в какой очередности запрашивать – дело немалой важности. Вспомним – чтобы считать\записать информацию, нужно отправить жесткому диску адреса секторов (сейчас стандартным размером сектора считается 4 килобайта, а адресация используется линейная = LBA), после чего электроника диска должна правильно cпозиционировать считывающую головку, дождаться нужного сектора на блине и произвести требуемую операцию с данными. Эти действия с точки зрения электроники очень дорогие – они стоят огромную кучу времени, за которое пройдет не один миллион тактов процессора.
Сразу возьмем в оборот фиолетовый слой драйвера и оранжевый слой hardware на схеме – они также напрямую связаны с очередностью команд, поступающих жесткому диску. Вместе с SATA интерфейсом в ПК пришли такие штуки как AHCI – расширенный набор инструкций для общения с микропрограммой контроллера HDD, а вместе с ним и NCQ – планировщик команд внутри самого жесткого диска.
Хочется обратить внимание на большой вертикальный блок “ядро” на схеме. Оно ведет нас практически на протяжении всего пути – все находится по его непрерывным контролем. После того, как процесс из userspace начинает I/O операцию, ядро берет задачу в свои руки и доводит дело до самого контроллера жесткого диска. Через драйвер отдаёт ему команды и получает от него ответную информацию, которую возвращает процессу.
Scheduling
Итак, мы выяснили, что из-за самой конструкции жестких дисков очень сложно получить большие скорости чтения\записи, и остается только оптимизировать то что есть.
ReadAhead – механизм, при котором ядро, когда процесс делает запрос на чтение, старается угадать какое количество блоков данных будет прочитано. Предположим, что процессу нужно произвести линейное чтение большого количества данных (скопировать фильм с диска на диск, например). В этом случае логично предположить, что вместо постоянных I\O запросов на чтение по 4 килобайта, проще сделать один запрос на весь размер данных в 4 гигабайта, и, тем самым, уменьшить количество генерируемых IOps в миллион раз (по факту, конечно, такие большие seqential reads не делаются, потому что за время его выполнения большому количеству других процессов нужны дисковые ресурсы). Таким образом, “опережающее чтение” работает в тесной связке с дисковым буфером (блок кэширование операций на схеме).
Помимо ReadAhead существует технология, так называемой, “Out of order” доставки информации, и работает уже на уровне прошивки диска. Ее смысл заключается в том, что необязательно чтение начинать с самого первого запрошенного сектора, по пути к нему можно прочитать и другие, если они являются частью запрошенного блока данных.
I\O scheduling – методология построения очередей запросов к дисковой подсистеме. Ее задача на основании определенного алгоритма организовать максимально эффективную очередь, способную освободиться за самое короткое время. Вот основные алгоритмы:
- noop
- deadline
- cfq
- multi-queue: bfq и mq-deadline
noop – (no operation) простая FIFO очередь, по-сути, отсутствие планировщика.
deadline – алгоритм пытается предоставить примерно равное количество ресурсов всем операциям.
cfq – (completely fair scheduling) сложный алгоритм, подробности лучше найти в документации или просто на просторах интернета.
Следующие планировщики доступны только когда включен другой механизм передачи запросов дисковой подсистеме: multiqueue block layer.
mq-deadline – тот же deadline
bfq – наиболее свежий планировщик. Ни в одном дистрибутиве пока не идет по умолчанию, но, возможно, когда-нибудь это и произойдет. (PS: привет из 4 марта, в ядре версии 5.0 отключат старые планировщики и оставят bfq)
kyber – тоже новый алгоритм, с упором на чтение перед записью и мультипоточность. Больше ориентирован на сетевые блочные устройства. Следовательно, точно не подходит для HDD.
Посмотреть используемый планировщик для диска, к примеру sda:
cat /sys/class/block/sda/queue/schedulerИтак, в соответствии с планировщиком, ядро начинает сортировать запросы к диску и хранить в кэше. А с помощью операций sync или fsync ядро будет отдавать закэшированные операции на исполнение драйверу.
Опустимся на следующий уровень обмена, практически уровень железа. Вспомним различные виды и технологии:
- Во-первых, существует пачка различных интерфейсов подключения, такие PATA => SATA, SCSI=>SAS, PCI-E, M.2 и т.п.
- Во-вторых, протоколы передачи данных, PATA=IDE =>SATA1-2-3, SCSI (много версий) => SAS, NVMe, и др.
- Во-третьих, режимы работы интерфейса относительно архитектуры, это PIO, DMA, UDMA.
- В-четвертых, расширения протоколов и инструкций, это ATAPI, AHCI, NCQ и прочее.
Говоря проще, если мы упоминаем какой-нибудь SATA, то нужно помнить, что это стек технологий, а не просто разъем для подключения. И работать диск может весьма по-разному, в зависимости от того какие наборы технологий будут задействованы: одно дело когда включена эмуляция IDE и каким-то образом диск “свалился” в PIO, отчего еле шевелится, а другое дело – SATA3, включено AHCI с NCQ.
Забавно, но в разрезе I/O операций, работа контроллера жесткого диска во многом идентична работе операционной системы: в контроллере диска есть кэш, где хранятся последовательности команд, есть планировщик, который сортирует эту последовательность.
Обмолвимся и об SSD. Они, безусловно, лишены отличительных особенностей HDD: не имеют движущихся частей, имеют в разы меньшее время отклика и не нуждаются в большинстве оптимизаций. Контроллер сам распределит в какие ячейки памяти писать, чтобы они меньше изнашивались, и строит очереди команд по своим, отличным от механических дисков, правилам. Но важно, чтобы ОС знала о том, что ваш диск твердотельный – иначе большая часть технологий, накопленных за время существования обычных “винчестеров”, будет только мешать качественной работе SSD.
Подведем итог. Считать I\O – занятие крайне непоказательное, потому что у них слишком много варьирующихся параметров. Для определения bottleneck дисковой подсистемы, нужно учитывать все уровни ее работы, потому как засада может поджидать на любом из них. Возьмем это на заметку, а разбираться на практике продолжим в следующей части!
Что еще можно почитать:
- Whitepaper от seagate по поводу NCQ и не только – о большинстве базовых вещей касательно работы дисков.
- Whitepaper от Intel про их SSD