Разбираемся с тормозной файловой системой, часть 2: взгляд со стороны ОС
О секторах, блоках и адресации
Мне показалось очень нужным рассмотреть на низком уровне работу механических дисков (хотя и все равно поверхностно, как ни крути). Дело в том, что можно легко запутаться во всех этих секторах и блоках разных калибров. И у этого есть исторические аспекты. Маленько разберемся:
Сектор приз на барабане.
Сектором называется минимальная область диска, которая имеет адрес. Раньше дефолтным размером было 512 байт. Теперь современный стандарт – 4096 байт, известный как advanced format. Если коротко – на картинке выше изображен физический сектор. Логический сектор – это “виртуальный” размер сектора о котором может сообщать вам диск. Можно пронаблюдать через команду fdisk -l /dev/$device.
Кластер или блок.
Эти слова часто имеют очень путанное использование. Вроде как в линуксе слово “cluster” не применяется, либо можно считать его синонимичным определению блока. А вот блок… С ним часто происходят разночтения.
В первую очередь нужно закрепить понимание, что это просто абстракция, логическое представления единицы обрабатываемых данных. Порой, блоками называют как логические так и физические секторы диска, только подразумевая взгляд со стороны ОС. Как бы для диска это сектор, но для самой операционки это всего лишь некий абстрактный блок, который диск соизволил отдать (в случае SSD или некоторых SCSI это действительно “фиктивный” сектор). А иногда, слегка поднявшись по структуре блочных устройств, так называют структурные единицы уровня файловой системы. Это все является блоками, но без контекста можно запутаться. Я постараюсь не создавать двусмысленности в статьях, и не использовать слово “кластер” касательно файловой системы, и писать “физический сектор” или “логический сектор” там, где подразумевается именно соответствующий сектор.
Выравнивание разделов.
Как я уже упоминал, слово “блок” может использоваться при использовании различных сущностей: блок как логический сектор на диске, блок как структурная единица файловой системы, менеджера томов, RAID-массива. А ведь все это может вполне себе работать в связке. А теперь представьте, что внезапно каждая из этих сущностей считает блоком совсем не то, что считает другая. Это породило бы массу неприятностей…
На самом деле, такой исход маловероятен, но теоретически возможен. Впрочем, механизмы создания логических томов, RAIDов, ZFS пулов и прочего, автоматизировано умеют выравниваться вдоль разделов или всего диска или может даже друг друга (почему нет?). Но во-первых, так было не всегда, а во-вторых, иногда тоже есть нюансы. Итак зачем нужно выравнивание?
Запустив fdisk -l /dev/$device обратите внимание на размер логического и физического сектора и стартовый сектор. Скорее всего, у вас все в порядке, и будет такая картина:
Sector size (logical/physical): 512 bytes / 4096 bytesDevice Start
/dev/sda1 2048Проблема возникает, когда первым логическим сектором у вас является 63й.
Device Start
/dev/sda1 63Но почему именно 63?
Стандартной схемой всегда считалось начинать раздел сразу после окончания первой дорожки или цилиндра (track, cylinder).
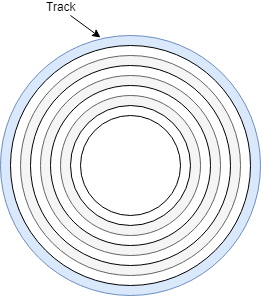
А при старом типе адресации CHS (cylinders, heads, sectors) адрес сектора в дорожке мог кодироваться только 6 битами (0-63).
На смену CHS пришел LBA (logical block address), добавляющий дополнительный уровень абстракции между адресацией диска и драйвера ОС. С тех пор напрямую с геометрией диска работать не принято, и используются уже много раз упомянутые логические секторы\блоки.
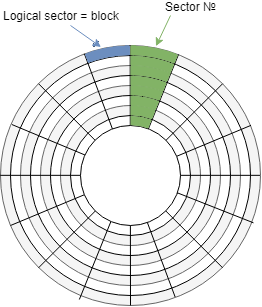
Двойственность понятия сектора
А теперь быстренько вернемся к недавней теме о секторах. Ведь с точки зрения окружности, нумерованный сектор, тот что выделен зеленым, это набор состоящий из уникальных физических секторов с каждого цилиндра и головки. И каждый раз, в нумерации CHS (цилиндр, головка, сектор), он отображает один и тот же номер физического сектора, с координатой (x,y,1), где x- номер цилиндра, y – номер головки, 1 – первый сектор (только нумерация секторов идет с единицы, всего остального с нуля).
Возможно, именно на границе перехода с CHS на LBA так сильно перемешались понятия логических\физических\блоков\секторов, ведь, как только появился дополнительный слой абстракции, пропала эта явная связь между сектором окружности и адресом, а его логический адрес перестал отображать физическое расположение.
Если вернуться к Advanced Format, при котором физический сектор больше логического, то по нашему “блинчику” это выглядит так:
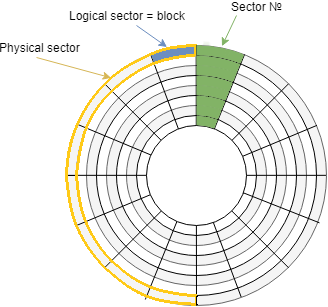
Логический сектор 512 байт, физический 4096 байт
Теперь к сути выравнивания.
И если как-то сошлись звезды, и у вас “недоехал” раздел до 2048-го (кстати, или любого другого, кратного 4 килобайтам, пусть даже 64-го), то ситуация будет выглядеть следующим образом:

Видно что 4k блоки файловой системы съехали на 512 байт относительно 4k блоков диска. Такая ситуация порождает дополнительные накладные расходы, когда при работе с одним блоком, диску, по факту, приходится оперировать двумя.
В утилите parted есть даже команда проверки выравнивания.
# проверяем 1 раздел на выравнивание по начальному и конечному сектору
parted /dev/sda align-check optimal 1/sys/block/device
sysfs – виртуальная файловая система, в которой отражены значения различных переменных ядра.
В директории /sys/block будут все Ваши блочные устройства, а в директории устройства и в файле stat – статистика работы с этим устройством. Для начала, поглядим на них.
/sys/block/$device/stat
Информация взята из документации, где также присутствуют значения “discard” для ядер 4.19 и выше. На текущий момент такие ядра по дефолту есть только в rolling-release дистрибутивах, и потому здесь их не включил, тем паче, discard-операции применимы только для SSD и thin-provision устройств.
Получив значения (например командой cat) мы сможем наблюдать 11 цифр, разделенных табуляцией. Каждый “столбик” отображает свое значение.
- read I/Os
- read merges
- read sectors
- read ticks
- write I/Os
- write merges
- write sectors
- write ticks
- in-flight
- io-ticks
- time-in-queue
read и write I/O – количество завершенных I/O операций.
read и write merges – значение увеличивается, при присоединении нового I/O запроса к запросу в очереди. (вспоминаем, например readahead из прошлой части)
read и write sectors – количество прочитанных или записанных секторов
read и write ticks – произведение времени нахождения и количества запросов ожидающих в очереди или суммарное время ожидания I/O за секунду, в миллисекундах. Так, если в 60 запросов, в среднем, ждут 30 миллисекунд, то значение будет 30*60=1800ms
in_flight – I/O отправленные драйверу, но еще не выполненные. Сюда не входят те запросы, которые стоят в очереди.
io_ticks – время за секунду, при котором устройство имеет в очереди запросы. Что-то вроде утилизации.
time_in_queue – По документации это read + write ticks, но на практике я заметил что такая арифметика не выходит.
Эх, если бы я умел в С…

“Руками” эти метрики смотреть не очень информативно, а вот собирать системами мониторинга – очень даже.
/sys/block/$device/queue
В директории queue содержится большая часть интересностей.
Опять же, не хочется в тупую заниматься переводом документации, поэтому постараюсь привести только максимально полезные данные. Полный список в доках по ссылке выше. Также часть параметров есть в русских доках по redhat 6.
Итак, в директории /sys/block/$device/queue можно найти следующие файлы, cat’нув которые, получим значения:
add_random (RW) – (RW означает что параметр доступен для перезаписи, RO – только чтение). Забавно, но есть так называемая “энтропия диска“, которую используют для генерации случайных чисел. Этим параметром можно ее включать (1)\выключать (0).
physical_block_size (RO) – размер физического сектора на диске. Как видите, в названии параметра написано блок, то есть по-сути это размер сектора о котором сообщает нам диск.
logical_block_size (RO) – размер логического сектора диска.
max_hw_sectors_kb (RO) – несмотря на слово “сектор”, это максимальный возможный размер переданных за один запрос данных в килобайтах. Т.е. по-сути это максимальный размер чего? Надеюсь, вы догадались, это максимальный размер I\O.
max_sectors_kb (RW) – здесь как раз мы задаем ограничение на размер I/O. Я всегда по умолчанию наблюдал значение 1280 кб, но оно вроде может и варьироваться, но не знаю по каким критериям. Это значение, что логично, нельзя выставить больше чем max_hw_sectors_kb.
minimum_io_size (RO) – минимальный размер I/O. Ожидаемо, следует из размера логического сектора.
nomerges (RW) – объединение запросов. 0 – алгоритмы работают на полную катушку, 1 – только простые, 2- полностью отключено.
nr_requests (RW) – Число запросов чтения или записи в очереди. Если очередь переполнилась, процесс будет ждать ее освобождения.
optimal_io_size (RO) – некоторые устройства умеют сообщать оптимальный размер I/O для себя.
read_ahead_kb (RW) – размер упреждающего чтения (было в первой части цикла).
rotational (RW) – параметр, определяющий является ли диск механическим или нет. Если выставить значение вручную, то можно превратить обычный HDD в SSD для диска будут использоваться соответствующие оптимизации.
write_cache (RW) – режим работы write back (запись в кэш) или write through (мимо кэша ОС). Хоть значение и RW, его лучше не изменять, так как оно изменяет лишь видение ситуации со стороны ядра, но не диска. WriteThrough подразумевается тогда, когда кэшированием занимается другое устройство, например RAID-контроллер.
Грязный гарри (Dirty Pages)
Dirty pages – специальных механизм отложенной записи на диск, при котором хранящиеся в памяти данные помечаются “грязными”, то есть ожидающими записи на диск. По-сути, является одной из структурных частей механизма дискового кэширования. Учтем это, и пойдем дальше.
/proc/sys/vm/
По отработанной схеме, переведу только описание параметров имеющих корреляцию с темой работы дисков.
dirty_background_bytes и dirty_background_ratio – Отражает ограничение по количеству памяти с страницами, превышение которого обязывает ядро начать сбрасывать страницы на диск. Может быть, соответственно задано жестко в байтах либо в процентном отношении от доступной памяти системы. Обнуляют значения друг друга.
Если что, “доступная память” не равно “вся память системы”. Доступную память, как и dirty pages можно пронаблюдать в /proc/meminfo.
grep -e "Dirty\|MemAvailable" /proc/meminfoПодробнее про meminfo в доках редхат.
dirty_bytes и dirty_ratio – Это лимит на количество dirty pages которое не должно быть превышено. Так же, либо в байтах , либо в процентах от MemAvailable.
dirty_writeback_centisecs – время “протухания” dirty pages, это максимальное время, которое они могут хранится в памяти до сброса на диск. Указано в сотых долях секунды.
dirty_writeback_centisecs – как часто просыпается поллер pdflush, чтобы выполнить сброс dirty-bytes на диск.
Таким образом, dirty pages у нас имеют право без проблем накапливаться до значения dirty_background_ratio либо пока не истечет время их нахождения в памяти равное dirty_writeback_centisecs, после чего они начинают сбрасываться на диск. При этом они могут продолжать накапливаться, покуда не достигнут своего предела dirty_ratio.
laptop_mode – интересный режим, подразумевает что если на текущий момент ОС загружена на устройстве с аккумулятором и не подключена к питанию, то нужно использовать специальный механизм сброса dirty pages. Суть режима заключается в следующем: раз на первый план вынесено энергопотребление, то нужно максимально сократить время работы механической части диска – его вращения и раскрутки. Для этого категорически не подходит обычная логика работы сброса кэшей (описанная выше), так как она способствует “размазыванию” нагрузки на диск во времени. Следовательно, для компоновки и разнесения обращений к диску, сброс dirty pages производится только если диск уже находится в движении, например, после read i/o. Время жизни dirty pages возрастает до 10 минут (можно изменить). Присутствует много интересностей, типо возможности сильно задрать readahead или сменить частоту CPU. Подробнее, как обычно, в документации.
Я думаю, с глухой теорией пора завязывать. В следующей части мы рассмотрим базовые инструменты для мониторинга дисков.
Доп информация:
Хорошая презенташка от Christoph Anton Mitterer, взято отсюда: https://www.dcache.org