Разбираемся с тормозной файловой системой, часть 1: теория
Так уж получилось, что я любитель пробовать все самое новенькое и продвинутое. И когда я планировал миграцию домашнего сервачка с убунты на proxmox, то решил что хочу попробовать что-то экстравагантное. У меня уже был небольшой опыт пользования BTRFS и ZFS, да и LVM2, а хотелось попробовать все. Хотя история с развалившейся ext4, которой не помог журнал, еще не успела меня подкосить, я все же уже был повернут лицом к таким важным технологиям как soft-RAID, volume management, snapshots и, непосредственно, регулярный бекап. Так как я нищеброд, то в распоряжении у меня было очень мало дисковых ресурсов, а распределить место хотелось максимально эффективно. Пришлось как следует поколхозить!
Под систему и сервисы я смог выделить два однотерабайтных HDD и один на 500Gb. Логика подсказывает, с дисками разного размера много каши не сваришь: зазеркалить не получится (да и зачем зеркало из трех дисков?), сделать RAID5 тоже.
Но линкусовый софт-рейд mdadm работает с разделами – собственно чтобы собрать к примеру raid1 из двух дисков, нужно создать на каждом из них соответствующий раздел с меткой “Linux RAID” и уже из этих разделов дальше собирать зеркало. К тому же, это в моем случае было обязательно еще и просто потому, что загрузчику UEFI нужно увидеть на диске раздел fat32, на котором уже загрузить grub а потом kernel + initramfs. Если этот efi-раздел будет с неправильной меткой, то загрузчик его не воспримет.
В итоге собрать все это непотребство я решил таким образом:
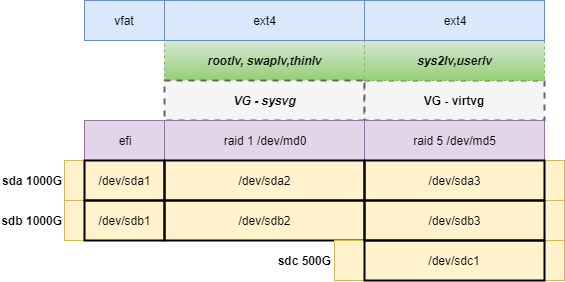
Получился раздел /dev/md0 на 500 Гб, состоящих из двух зеркалируемых разделов sda2 и sdb2, а также раздел /dev/md5 на 1ТБ состоящий из трех разделов по 500 Гб: sda3, sdb3, sdc1.
К слову сказать, все эти sda, sdb, sdc самому mdadm’у до лампочки: при создании массива всю служебную информацию он записывает в специальный суперблок и при загрузке системы сам собирает все диски как надо. Независимо от уровня рейда, достаточно иметь суперблок от одного диска, чтобы знать к какому массиву он принадлежит, сколько в нем всего должно быть дисков и т.п.
На md0 (все же следовало бы назвать его md1) создана группа томов LVM sysvg, а в ней логические тома: rootlv (для самой системы) swaplv (понятно, раздел подкачки) и thinlv (специальный тонкий том).
На md5 также создана volume group с двумя томами, один тоже под системные контейнеры, один для пользователей.
Рядом из трех дисков был собран raidz, представляющий собой нечто похожее на RAID5, только средствами ZOL (ZFS on linux). На схеме его нет, возможно речь о нем пойдет в другой статье.
Все это было успешно развернуто и работало, хотя и попахивало тормозами. Обрастало контейнерами и виртуалками, как-то, в общем, жило. В то, как это работало без тормозов, вносил свой вклад еще и тот самый raidz, с которого были смонтированы файловые системы, на которых хранится, непосредственно, полезная нагрузка. Он как раз работает без нареканий, быстро и качественно.
Когда пришло время хоть сколько-нибудь значимых нагрузок на системные сервисы, и когда их просто стало достаточно много (они же все еще и логи пишут) то начались проблемы – отзывчивость сервака упала до совсем низких пределов – спасало только то, что не использовался swap, иначе бы система была практически в лежачем состоянии.
И я начал изучать теорию.
Продолжение на следующей странице