Разбираемся с тормозной файловой системой, часть 3: базовые инструменты.

В прошлой части мы изучили теорию того, как ориентировочно выглядят дисковые операции и на какие компоненты линукса они завязаны. Теперь же нам нужно обратить внимание на практические навыки – как посмотреть те или иные показатели и как их корректно интерпретировать.
Когда я только начал замечать проблемы и полез в гугл за ответами, со всех сторон начали сыпаться советы по тестированию скорости диска с помощью утилиты dd.
dd
Как написано в man’е, производит конвертирование и копирование файла. Описание очень скудное и не дает представления о том на что способна эта замечательная программа.
Это не сильно соотносится сейчас с нашей темой, но принцип устройства VFS предполагает что буквально все в системе должно быть представлено как “файл”, в том числе и устройства. С этим связано одно из самый популярных применений dd – возможность побайтово склонировать целый диск, раздел, или какую-то их часть.
dd if=/dev/sda of=/dev/sdbКоманда выше полностью скопирует информацию с одного диска на другой со всеми “потрохами”: идентификаторами разделов, файловыми системами, метаданными и полезной нагрузкой.
Добавив status=progress можно будет наблюдать за течением сего процесса.
Также, например, если не указывать куда перенаправлять вывод (без директивы of=), то вывод просто получим на экран (stdout).
dd if=/etc/os-releaseВпрочем, в мане или на просторах сети полно информации о дэдэшечке, не будем повторяться.
Вернемся лучше к нашим баранам, мы собирались измерить скорость работы дисков. Как правило самые ходовые тесты заключаются в копировании файлов с места на место или копирование нулей в файл.
Вот мы типо пишем 1 гигабайт:
> dd if=/dev/zero of=/tmp/testfile bs=1G count=1
1073741824 bytes (1,1 GB, 1,0 GiB) copied, 10,0035 s, 107 MB/sТеперь пробежимся по значимым опциям.
bs = размер блока. Т.к dd работает именно поблочно, то это будет размером его атомарной операции, считать n байт => записать n байт, ни больше ни меньше. Поддерживается указание арифметических операций, например bs=2x80x18b (размер дискеты). По умолчанию bs равен 512b
count = тут понятно, это просто счетчик.
status = progress – периодически отписываться в stderr о прогрессе.
iflag \ oflag = чтение или запись может производится особым образом.
- direct – отправлять запросы минуя кэш (direct I/O)
- dsync – использовать синхронное I/O (synchronized I/O), т.е. каждое последующее IO только после завершения предыдущего.
conv = обработка, которая происходит между in и out. В основном используется директива noerror, остальные весьма специфичны, и редко встречались или требовались мне на практике.
Таким образом, можно проводить тесты линейной записи или чтения.
Можно регулировать размер блока, который будет записан\прочитан.
Есть возможность писать, с просьбой ядру не использовать кэш.
Можно использовать синхронное I/O.
Подводя некий итог, можно понять что dd может достаточно хорошо отрабатывать простые синтетические тесты, и позволяет оценить некоторые параметры работы дисков. Но реальную нагрузку и производительность дисковой подсистемы с ее помощью оценить
нереально.
А нам надо видеть чем занимаются диски. Разбираемся дальше.
iotop
Аналог top, только типо для дисков.
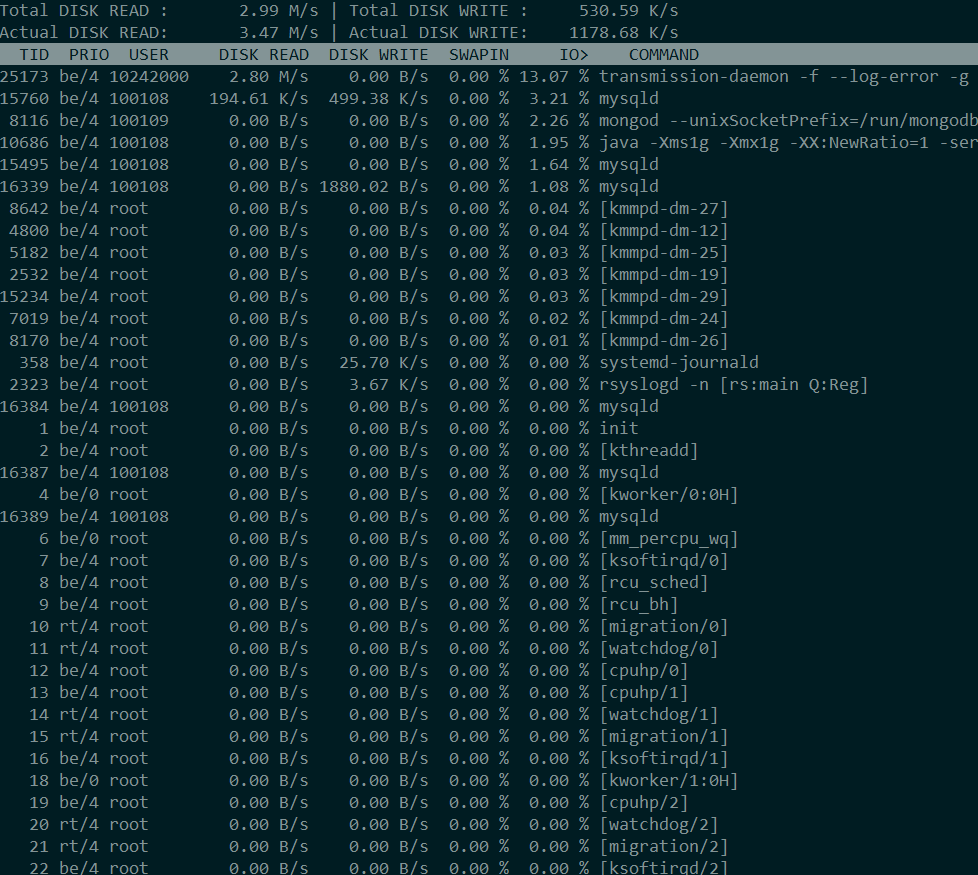
Можно наблюдать список процессов, и различные показатели по столбцам: thread ID, IO приоритет, пользователя, интенсивность свопа и некий процент IO.
IO priority – be\rt\id означают класс процесса (best-effort, real-time, idle), а значение от 0 до 7 приоритет относительно других процессов (меньшие значения подразумевают больший приоритет). Эти значения можно изменить с помощью утилиты ionice, но помните, что приоритеты смотрит I/O scheduler, упоминаемый в предыдущей статье. И умеют это только “весовые” виды планировщиков, т.е. CFQ, BFQ и Kyber (насчет него неточно). Также, приоритеты не работают для асинхронной записи.
Swap – так как процессу отводится некоторая часть всей очереди на ввод-вывод, то процент от этой части, являющийся свопингом будет отображен в этом значении.
I/O – работает по тому же принципу что и swap, но отображает время затрачиваемое на ожидание ввода-вывода.
Также в верхней части экрана есть значения {Total,Actual} DISK {READ,WRITE}. Как написано в мане, Total read\write подразумевает весь обмен между процессами и дисковой подсистемой ядра.
Actual read\write – обмен между дисковой подсистемой ядра и драйверами оборудования.
Таким образом значения Total и Actual могут ощутимо отличаться как раз таки из-за кэша и планировщика.
Ключи
-a – iotop будет показывать аккумулированные данные с момента своего запуска. В таком режиме информация получается более наглядной.
-o – показывать только те процессы, у которых есть активность.
-d – интервал обновления.
-P – показывать не треды а процессы.
На самом деле, каких-то действительно полезных аналитических данных через iotop у меня не получалось добыть. Главное причина тому – нет разделения по блочным устройствам, показываются данные по всей системе целиком. Но в роли подспорья утилита однозначно хороша.
iostat
Является частью пакета sysstat.
Тулза для мониторинга блочных устройств.
Если просто просто ее запустить без ключей, то получим средние значения по всем дискам с момента загрузки системы.
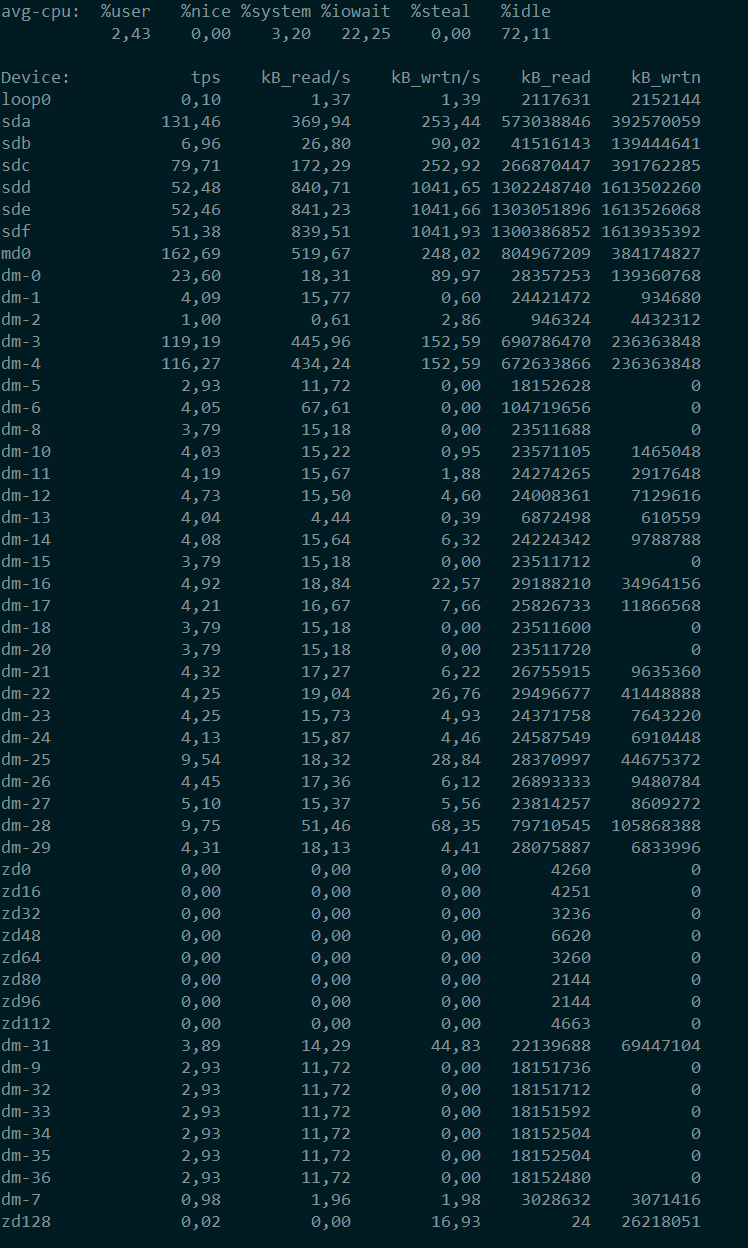
Если же запускать в формате iostat число1 число2, то механизм работы будет следующим: число1 – это как часто опрашивать статистику, число2 – количество опросов. iostat 2 10 – опросить каждые 2 секунды,
всего 10 раз .
В верхней строчке идет статистика по CPU.
В принципе, все это можно увидеть в top:
%user – загрузка процессами выполняющимися в userpspace.
%nice – тот же userspace, но то что выполняется с настройками nice – определяющими приоритет у дискового шедулера
%system – то что кушают ядерные процессы
%iowait – процент времени которые CPU ждет ответа от дисковой подсистемы
%steal (может отсутствовать) – как правило, встречается в виртуализации, когда виртуальные машины бьются друг с другом за ресурсы
%idle – CPU отдыхает
Значения:
tps – количество I/O запросов устройству. Судя по ману, здесь отображаются запросы уже после их комбинирования планировщиком.
Без дополнительных ключей, остальные столбцы, думаю, понятны – запись и чтение в секунду, и сколько всего было записано\прочитано.
Другое дело с ключиком -х:
rrqm/s и wrqm/s – количество объединенных запросов чтения и записи соответственно.
r/s и w/s – количество i/o на чтение и запись в секунду.
rkB/s и wkB/s – чтение и запись в КБ\сек.
avgrq-sz – средний размер отправленных запросов (в секторах).
avgqu-sz – средняя длина очереди.
await, r_await, w_await – время запроса в очереди, плюс время на его обслуживание.
util – время в течении которого блочное устройство занято запросами на I/O в процентах.
В новых версиях iostat слегка изменились некоторые столбцы.
Добавились %rrqm и %wrqm – процент объединенных запросов.
areq-sz – средний размер запросов (бывший avgrq-sz, но в отличие от него не в секторах, а в килобайтах).
aqu-sz – средняя длина очереди (бывший avgqu-sz)
rareq-sz, wareq-sz – средний размер запроса для чтения\записи.
Кратко о ключах:
- с – только статистика по CPU.
- d – убрать статистику по CPU, только диски.
- g – позволяет группировать диски и отображать по ним суммарные значения. например: iostat -g my_disk_group sda sdb sdc. Получим статистику по трем дискам и их сумму в группе my_disk_group.
- H – вместе с -g уберет из вывода отдельные диски, оставив только суммарные значения по группе.
- h – human readable, но, как по мне, удобств не добавляет.
- j { ID | LABEL | PATH | UUID | … } – вывести название диска в указанном формате, по умолчанию LABEL.
- k и m – отображать значения в килобайтах или мегабайтах соответственно.
- N – использовать имена для device mapper томов. Удобно для LVM.
- p – отображать разделы
- t – штамп времени каждого отчета
- x – расширенная статистика.
- y – не показывать первый отчет, который показывает общую статистику с момента загрузки.
- z – не показывать устройства с неизменными значениями (типо неактивные).
/proc/sys/vm/block_dump
Можно включить отладку сброса dirty pages на диск.
echo 1 > /proc/sys/vm/block_dumpСообщения о том, данные какого процесса сбрасываются можно увидеть в dmesg или логах ядра (количество сообщений пропорционально интенсивности записи, будьте готовы к срачу в логах)
Домашняя работа
А теперь на основании теоретических знаний из первой статьи и практических инструментов из текущей, попробуйте понять что происходит с линейной записью в этих четырех случаях, и почему получаются именно такие результаты? Какое узкое место системы в данном случае проявляется? Запись производится на один диск, файловая система XFS.
> dd if=/dev/zero of=/tmp/testfile bs=4k count=200000
...
819200000 байт (819 MB, 781 MiB) скопирован, 5,26288 s, 156 MB/s > dd if=/dev/zero of=/tmp/testfile bs=781M count=1 oflag=direct
...
818937856 байт (819 MB, 781 MiB) скопирован, 8,7302 s, 93,8 MB/s> dd if=/dev/zero of=/tmp/testfile bs=4k count=200000 oflag=direct
...
819200000 байт (819 MB, 781 MiB) скопирован, 39,5175 s, 20,7 MB/s> dd if=/dev/zero of=/tmp/testfile bs=4k count=2000 oflag=dsync
...
8192000 байт (8,2 MB, 7,8 MiB) скопирован, 60,7651 s, 135 kB/sВ последнем примере специально количество блоков меньше в сто раз, потому что иначе очень долго ждать 🙂
Попробуйте эти команды у себя (на ext4 результаты отличаться не будут), удостоверьтесь что результат не из головы.
Ответ будет в отдельном посте или в следующей части. Всех благ!